Research Summary
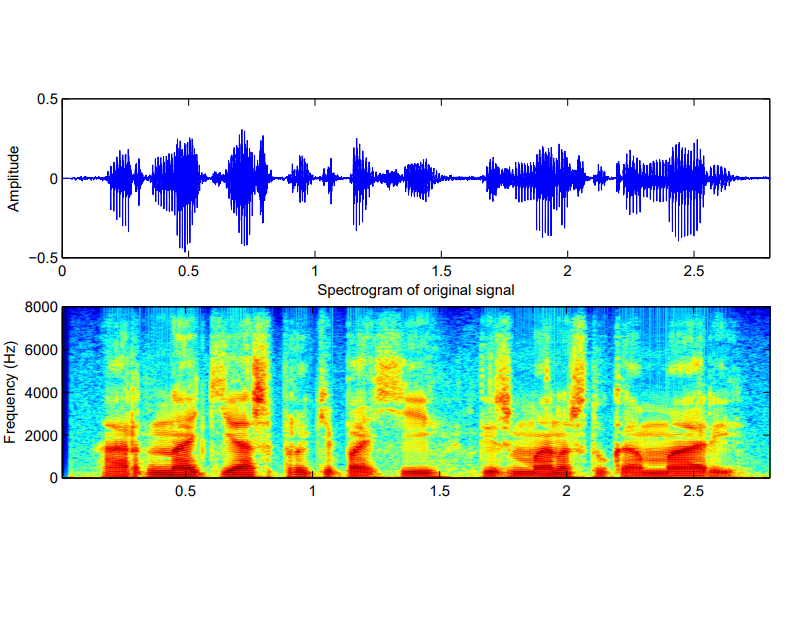
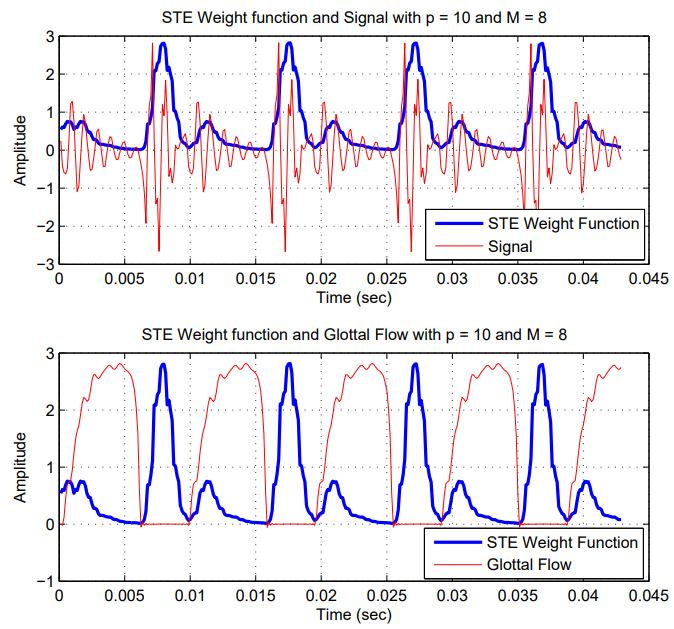
Speech and audio analysis constitute the core of my research activity, with particular emphasis on speech signal modeling, decomposition, transformation, and machine-learning-based interpretation. A substantial part of my Ph.D. work focused on the development of adaptive sinusoidal models for speech, where the signal is represented through time-varying amplitude- and phase-modulated components. Accurate parameter estimation in such models enables high-quality speech modifications, including time- and pitch-scale transformations, while precise speech decomposition can support downstream applications such as speech synthesis, emotion recognition, audio analysis, and musical instrument sound modeling. More broadly, my work has addressed several aspects of speech signal processing, including inverse filtering, glottal analysis, vocoding, speech transformation, text-to-speech synthesis, and acoustic modeling.
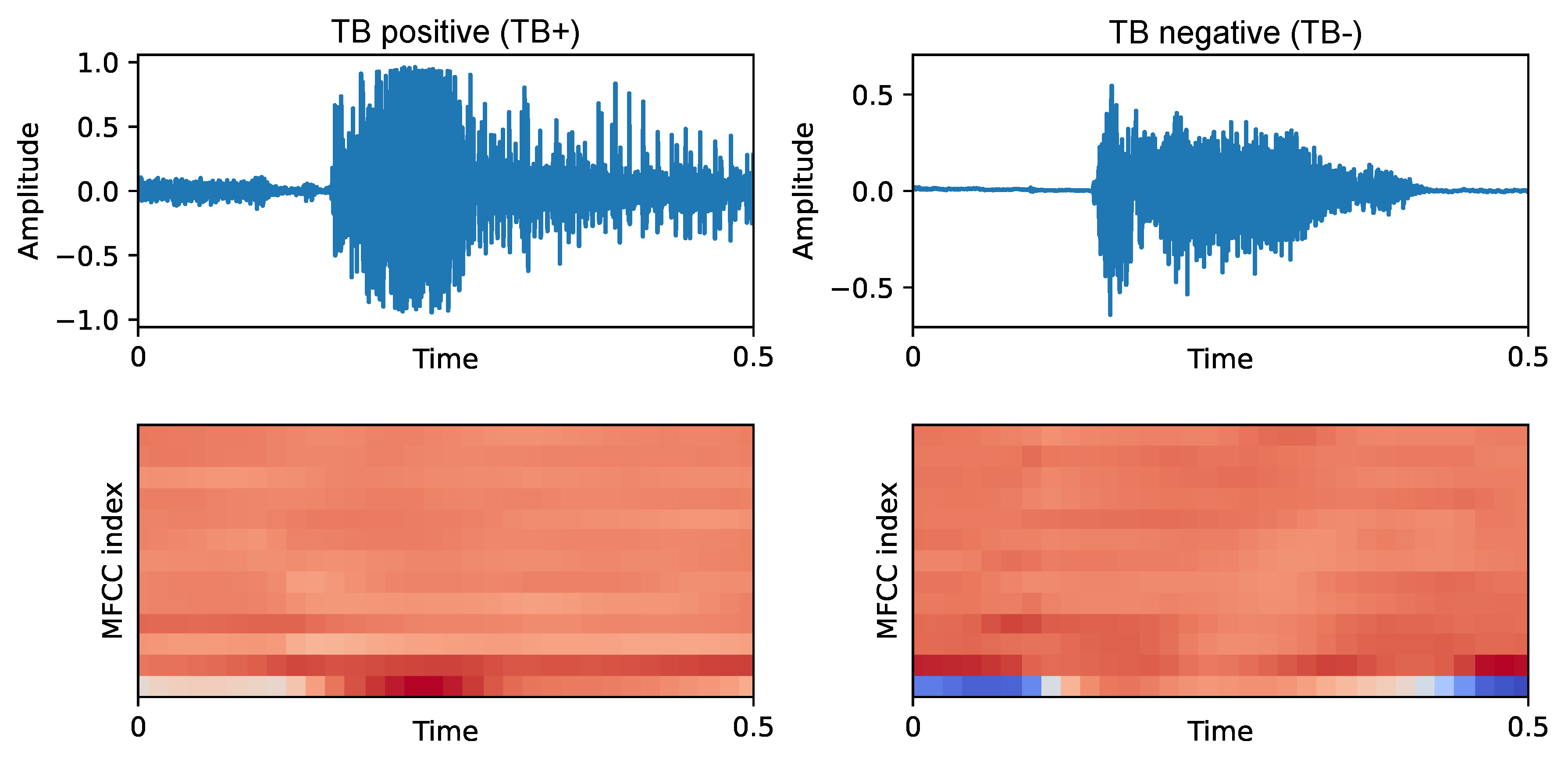
My current research interests extend toward machine learning and deep learning methods for speech, audio, and healthcare-oriented acoustic intelligence. I am particularly interested in pathological speech and voice analysis from the perspective of source-filter separation, since non-invasive glottal analysis may provide clinically useful information about vocal-fold function in a cost-effective way. In parallel, I am interested in affective speech processing, including emotion recognition from speech and the extraction of either data-driven or knowledge-based acoustic representations that can define a compact, interpretable emotional space useful in engineering, cognitive science, psychology, and related fields. More recently, my research has also expanded to cough and respiratory audio analysis, acoustic event detection, and predictive modeling for healthcare applications, combining classical signal processing expertise with modern machine learning and deep learning methodologies.
You can find my resume here
Interests
- Speech Signal Processing
- Affective Computing
- Machine/Deep Learning
- Pathological Speech Processing
- Audio Signal Processing
- Biosignal Processing