| ΗΥ-225: Οργάνωση Υπολογιστών
Άνοιξη 2005 |
Τμ. Επ. Υπολογιστών © Πανεπιστήμιο Κρήτης |
Σειρά Ασκήσεων 3:
Προσπελάσεις Μνήμης στον MIPS
Προθεσμία έως Τρίτη 8 Μαρτίου 2005, ώρα 23:59 (βδομάδα 3)
|
[Up: Table of Contents] [Prev: 2. Loops, SPIM I/O] |
[printer version, in PDF] [Next: 5. Instruction Formats] |
3.1 Προσπελάσεις Μνήμης: Εντολές load και store
Ο MIPS, όπως και οι άλλοι επεξεργαστές τύπου RISC, δεν έχει εντολές που να κάνουν αριθμητικές πράξεις πάνω σε τελεστέους που βρίσκονται στη μνήμη --όλες οι αριθμητικές πράξεις του γίνονται πάνω σε καταχωρητές ή σταθερές ποσότητες (immediate constants). Ο μόνος τρόπος να επεξεργαστούμε τα περιεχόμενα της μνήμης είναι πρώτα να αντιγράψουμε μιά λέξη (32 bits), ή μία μισή λέξη (16 bits), ή ένα byte (8 bits) από τη μνήμη σ' ένα καταχωρητή της CPU, να την επεξεργαστούμε σε καταχωρητές, και τέλος να αντιγράψουμε το αποτέλεσμα από έναν καταχωρητή στη μνήμη. Οι λόγοι είναι (α) γιά απλότητα του hardware, και (β) γιατί δεν θα πετυχαίναμε ψηλότερη ταχύτητα αν μία μόνη εντολή έκανε και την αντιγραφή και την επεξεργασία, όπως διδάσκεται στο μάθημα ΗΥ-425 (Αρχιτεκτονική Υπολογιστών).Αντιγραφή μιάς 32-μπιτης λέξης από τη μνήμη σ' ένα καταχωρητή ("φόρτωμα στον καταχωρητή") γίνεται με την εντολή "lw $rd, imm($rx)" (load word), όπου $rd είναι ο καταχωρητής προορισμού (destination register), και $rx είναι ένας καταχωρητής (index register) που περιέχει μιά διεύθυνση μνήμης στην οποία προστίθεται ο σταθερός αριθμός imm και το αποτέλεσμα της πρόσθεσης είναι η τελική διεύθυνση μνήμης απ' όπου γίνεται η αντιγραφή στον $rd. Συχνά, συμβολίζουμε τη μνήμη σαν έναν πίνακα (array) M[ ], και γράφουμε M[A] γιά να συμβολίσουμε το περιεχόμνο της θέσης μνήμης με διεύθυνση A. Έτσι, η παραπάνω εντολή lw $rd, imm($rx) προκαλεί ανάγνωση από τη διεύθυνση μνήμης (imm + $rx), δηλαδή διαβάζει το M[imm + $rx], και το γράφει στον καταχωρητή $rd.
Αντίστροφα, αντιγραφή μιάς 32-μπιτης λέξης από ένα καταχωρητή στη μνήμη ("αποθήκευση του καταχωρητή") γίνεται με την εντολή "sw $rs, imm($rx)" (store word), η οποία γράφει στη θέση μνήμης με διεύθυνση (imm + $rx), δηαλδή προκαλεί την αντιγραφή M[imm + $rx] <-- $rs. Εδώ, ο $rs είναι καταχωρητής πηγής (source register)· προσέξτε ότι σε αυτή την περίπτωση, ο τελεστέος πηγής (source operand) γράφεται αριστερά και ο τελεστέος προορισμού δεξιά μέσα στην εντολή Assembly, αντίθετα δηλαδή από τις εντολές αριθμητικών πράξεων και από την εντολή load.
3.2 Διευθύνσεις Bytes και Περιορισμοί Ευθυγράμμισης:
Οι διευθύνσεις μνήμης στον MIPS, όπως και σχεδόν σε όλους τους μοντέρνους επεξεργαστές, αναφέρονται σε Bytes στη μνήμη, δηλαδή ο MIPS είναι "Byte Addressable". Έτσι, μιά 32-μπιτη λέξη (π.χ. ένας ακέραιος) καταλαμβάνει 4 "θέσεις μνήμης" (4 bytes). Κατά συνέπεια, ένας πίνακας (array) μεγέθους 100 ακεραίων "πιάνει" 400 (συνεχόμενες) διευθύνσεις (θέσεις) στη μνήμη. Σ' ένα τέτοιο πίνακα, η διεύθυνση του κάθε ακέραιου διαφέρει από αυτήν του διπλανού του κατά 4. Εαν A0 είναι η διεύθυνση του "πρώτου" (μηδενικού) στοιχείου, a[0], ενός πίνακα ακεραίων της C, τότε το στοιχείο a[ i ] του πίνακα αυτού θα βρίσκεται στη διεύθυνση (A0 + 4*i). Αν ο πίνακας αυτός ήταν πίνακας χαρακτήρων (char), τότε το στοιχείο a[ i ] θα ήταν στη διεύθυνση (A0 + i).Τα 4 bytes που αποτελούν έναν ακέραιο έχουν διευθύνσεις που είναι συνεχόμενοι αριθμοί. Διεύθυνση του ακεραίου είναι η διεύθυνση εκείνου από τα 4 bytes του που έχει τη μικρότερη ("πρώτη") από τις 4 διευθύνσεις. Ο MIPS επιβάλει περιορισμούς ευθυγράμμισης (alignment restrictions) στις ποσότητες που προσπελαύνουν οι εντολές load και store στη μνήμη: μία ποσότητα μεγέθους N bytes επιβάλεται να έχει διεύθυνση που να είναι ακέραιο πολλαπλάσιο του N. Ετσι, όταν το N είναι δύναμη του 2, η διεύθυνση κάθε τέτοιας ποσότητας τελειώνει σ' ένα αντίστοιχο πλήθος μηδενικών, και η διεύθυνση των υπολοίπων bytes της ποσότητας διαφέρει μόνο σε αυτά τα λιγότερο σημαντικά (least significant) bits. Λόγω αυτού του περιορισμού, όταν η φυσική μνήμη έχει πλάτος N bytes, αρκεί μία μόνο προσπέλαση σε αυτήν γιά κάθε πρόσβαση σε ποσότητα μεγέθους N bytes.
3.3 Αρίθμηση των Bytes: Μηχανές Big-Endian και Little-Endian
Όταν αποθηκεύεται στη μνήμη ενός υπολογιστή μιά ποσότητα αποτελούμενη από πολλαπλά bytes (π.χ. ένας ακέραιος), πρέπει να καθοριστεί με ποιά σειρά αριθμούνται (διευθυνσιοδοτούνται) τα επιμέρους bytes μέσα στην ποσότητα αυτή. Δυστυχώς, δεν έχει υπάρξει συμφωνία μεταξύ των μεγάλων εταιρειών κατασκευής επεξεργαστών γιά τη σειρά αυτή, με συνέπεια να υπάρχουν δύο διαφορετικοί τύποι επεξεργαστών σήμερα --οι επονομαζόμενοι "big-endian" και οι επονομαζόμενοι "little-endian".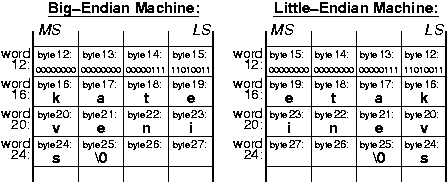
Ας ξεκινήσουμε με μιά σύμβαση που αφορά τον τρόπο σχεδιασμού στο χαρτί των ποσοτήτων που αποτελούνται από πολλαπλά bytes: Μέσα σ' έναν ακέραιο αριθμό, τα bits εκείνα που πολλαπλασιάζονται επί τις μεγαλύτερες δυνάμεις του 2 γιά να μας δώσουν την αριθμητική τιμή του ακεραίου λέγονται "περισσότερο σημαντικά" (MS - most significant) bits, και αυτά που πολλαπλασιάζονται επί τις μικρότερες δυνάμεις του 2 λέγονται "λιγότερο σημαντικά" (LS - least significant) bits. Το byte που περιέχει τα MS bits λέγεται MS byte, και εκείνο που περιέχει τα LS bits λέγεται LS byte. Όποτε σχεδιάζουμε έναν ακέραιο στο χαρτί, οριζόντια, θα βάζουμε πάντα τα MS bits και byte αριστερά, και τα LS bits και byte δεξιά, δηλαδή όπως και στους δεκαδικούς αριθμούς (φυσικά, η σύμβαση αυτή αφορά μόνο τους ανθρώπους --μέσα στον υπολογιστή δεν έχει νόημα να μιλάμε γιά "αριστερά transistors" και "δεξιά transistors"...). Ακολουθώντας τη σύμβαση αυτή, το σχήμα δείχνει ένα παράδειγμα τεσσάρων (4) λέξεων μνήμης (16 bytes) ενός 32-μπιτου υπολογιστή σε μία μηχανή "big-endian" και σε μία μηχανή "little-endian". Η πρώτη λέξη περιέχει τον ακέραιο αριθμό 2003 (δεκαδικό) = 7D3 (δεκαεξαδικό), ενώ στις επόμενες 3 λέξεις υπάρχει ένας πίνακας χαρακτήρων (array of char) μεγέθους 10 στοιχείων, και περισσεύουν και δύο ελεύθερα bytes· ο πίνακας χαρακτήρων περιέχει το (null-terminated) string "katevenis" (κάθε byte θα περιέχει το δυαδικό κώδικα ASCII ενός χαρακτήρα --π.χ. το πρώτο byte θα περιέχει 01101011, που είναι ο κώδικας του 'k'-- αλλά εμείς, γιά ευκολία, δείχνουμε το συμβολιζόμενο χαρακτήρα).
- Big-Endian: Σε πολλούς υπολογιστές, το MS byte του κάθε ακεραίου έχει τη μικρότερη διεύθυνση, και οι διευθύνσεις των bytes του αυξάνουν (προχωρούν) καθώς προχωράμε "δεξιά", προς το LS byte του. Αυτοί οι υπολογιστές λέγονται "big-endian" διότι η αρίθμιση των bytes ξεκινά από το "big end", δηλαδή το MS byte.
- Little-Endian: Σε άλλους υπολογιστές, το LS byte του κάθε ακεραίου έχει τη μικρότερη διεύθυνση, και οι διευθύνσεις των bytes του αυξάνουν (προχωρούν) καθώς προχωράμε "αριστερά", προς το MS byte του. Αυτοί οι υπολογιστές λέγονται "little-endian" διότι η αρίθμιση των bytes ξεκινά από το "little end", δηλαδή το LS byte.
Το "endian-ness" του υπολογιστή, δηλαδή το αν είναι big-endian ή little-endian, δεν μας επηρεάζει όταν εργαζόμαστε σε ένα και μόνο μηχάνημα, και πάντα γράφουμε και διαβάζουμε την κάθε ποσότητα με τον ίδιο τύπο --πράγμα που είναι και το σωστό να κάνει κανείς-- δηλαδή όπου στη μνήμη γράφουμε string διαβάζουμε πάντα string, και όπου γράφουμε integer διαβάζουμε πάντα integer. Το "endian-ness" μας επηρεάζει όταν αλλάζουμε τύπο μεταξύ εγγραφής και ανάγνωσης --πράγμα ανορθόδοξο-- π.χ. γράφουμε κάπου ένα string και μετά το διαβάζουμε σαν integer, ή γράφουμε integer και διαβάζουμε string. Το σημαντικότερο όλων όμως είναι ότι το endian-ness του υπολογιστή πρέπει να λαμβάνεται υπ' όψη όταν μεταφέρονται δεδομένα μέσω δικτύου μεταξύ υπολογιστών. Συνήθως, τα προγράμματα μεταφοράς δεδομένων (π.χ. ftp) θεωρούν ότι μεταφέρουμε κείμενο (ASCII strings), και τοποθετούν τα bytes με την αντίστοιχη σειρά. Αν όμως μεταφέρουμε άλλες μορφές δεδομένων (π.χ. 32-μπιτους ακεραίους) μεταξύ υπολογιστών με διαφορετικό endian-ness, η σειρά αυτή θα ήταν λάθος: όπως οι χαρακτήρες k, a, t, e μεταφέρονται σαν e, t, a, k στο παραπάνω σχήμα από big-endian σε little-endian, έτσι και ο ακέραιος 2003 θα ερμηνεύονταν σαν 00, 00, 07, D3 (δεκαεξαδικό), και θα μεταφέρονταν σαν D3, 07, 00, 00, δηλαδή 11010011.00000111.00000000.00000000 (δυαδικό), που είναι ο αριθμός -754,515,968 (δεκαδικό, συμπλήρωμα ως προς 2). Γιά να γίνει σωστά η μεταφορά, πρέπει να δηλωθεί στο πρόγραμμα μεταφοράς ο τύπος των δεδομένων που μεταφέρονται (π.χ. εντολή "type" στο ftp).
§ 3.4 - Άσκηση 3.1: Πίνακας Ακεραίων
Γράψτε ένα πρόγραμμα σε Assembly του MIPS που να διαβάζει 8 ακεραίους από την κονσόλα, να τους αποθηκεύει σ' ένα πίνακα (array) στη μνήμη, και στη συνέχεια να τυπώνει τα εξαπλάσιά τους και με την αντίστροφη σειρά. Παραδώστε τον κώδικά σας κι ένα στιγμιότυπο από μιά επιτυχημένη εκτέλεσή του, όπως αναφέρεται στο τέλος.- Ξεκινήστε με όσα μάθατε στις ασκήσεις 2, αλλά εδώ θα χρειαστεί να χρησιμοποιήσετε και τις νέες εντολές προσπέλασης ακεραίων στη μνήμη "lw" και "sw".
- Χρησιμοποιήστε τις οδηγίες ".data", ".align", και ".space" του Assembler του SPIM (σελίδες A-47, A-48 του παραρτήματος του βιβλίου) γιά να κρατήστε χώρο στη μνήμη δεδομένων (data segment) γιά τον πίνακα "a[ ]", μεγέθους 8 ακεραίων, και σωστά ευθυγραμμισμένο γιά ακεραίους. Τοποθετήστε κατάλληλα το label "a" ώστε να μπορείτε πιό κάτω να αναφερθείτε στη διεύθυνση όπου αρχίζει ο χώρος που κρατήσατε.
- Στην αρχή του προγράμματός σας, τοποθετήστε τη διεύθυνση όπου αρχίζει ο πίνακας a[ ] σε έναν καταχωρητή. Τη διεύθυνση αυτή την ξέρει ο Assembler, αλλά εσείς πιθανότατα όχι (εκτός αν την είχατε δώσει σαν argument στην οδηγία .data). Επίσης, δεν ξέρετε αν η διεύθυνση αυτή χωρά σε 16 bits (ένα immediate) ή όχι. Σε όλα αυτά έρχεται να σας βοηθήσει η ψεύδοεντολή (pseudoinstruction) "la $rd, label" του Assembler του SPIM: αυτή λέει στον Assembler να γεννήσει μία ή δύο πραγματικές εντολές που τοποθετούν την πραγματική διεύθυνση του label στον καταχωρητή $rd (μία εντολή αν η διεύθυνση χωρά σε 16 bits, δύο εντολές αλλοιώς). Παράδειγμα χρήσης της ψευδοεντολής "la" θα βρείτε στην § 2.2, εκεί που ετοιμάζαμε τα ορίσματα γιά τις εκτυπώσεις strings.
- Στη συνέχεια, τυπώστε ένα prompt που να ζητά 8 ακεραίους σε 8 γραμμές.
- Μετά, μπείτε σ' ένα βρόχο που θα επαναληφθεί 8 φορές, και που κάθε φορά θα διαβάζει έναν αριθμό (μέσω καλέσματος συστήματος) και θα τον αποθηκεύει στην επόμενη θέση του πίνακα a[ ]. Επισημάνσεις: (i) Οι εντολές "beq" και "bne" γιά τη δημιουργία του βρόχου δέχονται μόνο καταχωρητές σαν τελεστέους, και όχι σταθερές ποσότητες (immediates). (ii) Η μοναδική διευθυνσιοδότηση (addressing mode) του MIPS είναι "σταθερή ποσότητα (immediate) + καταχωρητής" --μην χρησιμοποιήστε τις ψεύδοδιευθυνσιοδοτήσεις του SPIM (σελίδα A.45).
- Αφού βγείτε από τον προηγούμενο βρόχο, τυπώστε μιά διαχωριστική γραμμή, και μπείτε σ'έναν άλλο βρόχο, που θα επαναληφθεί και αυτός 8 φορές, και που θα επισκεφθεί τα στοιχεία του πίνακα "a[ ]" αλλά κατ' αντίστροφη σειρά. Γιά κάθε στοιχείο, θα το διαβάζει από τη μνήμη, θα το εξαπλασιάζει (χωρίς να πειράξει την τιμή στη μνήμη), και θα τυπώνει αυτό το εξαπλάσιο, στην ίδια γραμμή αλλά όχι "κολλητά" με το προηγούμενό του. Υπολογίστε το εξαπλάσιο μέσω τριών κατάλληλων εντολών πρόσθεσης (add).
- Τέλος, ξαναγυρίστε στην αρχή (όπως και στην άσκηση 2), ώστε η ίδια δουλειά να επαναλαμβάνεται επ' αόριστο.
§ 3.5 - Άσκηση 3.2: Υπολογιστές Big-Endian και Little-Endian
- Χρησιμοποιήστε τον SPIM γιά να βρείτε τον δυαδικό (δεκαεξαδικό) κώδικα εσωτερικής αναπαράστασης (κώδικα ASCII) των χαρακτήρων του Λατινικού αλφαβήτου, a, b, ..., z, A, ..., Z, και των αριθμητικών χαρακτήρων, 0, 1, ..., 9. Γιά να το πετύχετε, ορίστε σταθερές τύπου string όπως στην πρώτη σειρά ασκήσεων, και στη συνέχεια μπείτε στον SPIM και μελετήστε τα περιεχόμενα της μνήμης δεδομένων στο παράθυρο "Data Segments". Δώστε τις διαπιστώσεις σας σ' ένα μικρό κειμενάκι, με 3 στήλες: χαρακτήρας, κώδικας ASCII στο δεκαεξαδικό, κώδικας ASCII στο δυαδικό. Βάλτε αποσιωποιητικά και εξηγήστε εκεί που παρατηρείτε κάποια ομοιομορφία....
- Έστω ότι αποθηκεύουμε το null-terminated string "xyz" σε μία λέξη ενός 32-μπιτου υπολογιστή, και στη συνέχεια διαβάζουμε αυτή τη λέξη σαν να είναι (32-μπιτος) ακέραιος. Υπολογίστε με αριθμητικές πράξεις ποιόν ακέραιο θα διαβάσουμε (α) σε μιά μηχανή big-endian, και (β) σε μιά μηχανή little-endian. Δώστε την απάντησή σας, μαζί με τις αριθμητικές πράξεις που κάνατε, σ' ένα μικρό κειμενάκι (στο δεκαδικό).
- Επαληθεύστε την απάντησή σας μ' ένα μικρό πρόγραμμα στον SPIM: Ζητήστε από τον Assembler να βάλει το string στη μνήμη δεδομένων, και μέσα από το πρόγραμμά σας αντιγράψτε εκείνη τη λέξη (ολόκληρη!) σ' ένα καταχωρητή και ζητήστε να τυπωθεί (μ' ένα κάλεσμα συστήματος) σαν ακέραιος. Ο SPIM συμπεριφέρεται σαν big-endian ή σαν little-endian ανάλογα σε ποιόν υπολογιστή τρέχει! Σε τι υπολογιστή τον τρέξατε τον SPIM; Τι έβγαλε; Αν τον τρέξτε σε άλλο τύπο υπολογιστή, με επεξεργαστή άλλης εταιρείας, θα βγάλει άλλα; Παραδώστε το πρόγραμμά σας (πηγαίος κώδικας), τα συμπεράσματά σας σ' ένα μικρό κειμενάκι, κι ένα στιγμιότυπο (screen-dump) του τρεξίματος.
|
[Up: Table of Contents] [Prev: 2. Loops, SPIM I/O] |
[printer version, in PDF] [Next: 5. Instruction Formats] |
| Up to the Home Page of CS-225
|
© copyright
University of Crete, Greece.
Last updated: 28 Feb. 2005, by M. Katevenis. |